概要
TiDB 的 Coprocessor 概念灵感来自于 HBase, 目前 TiDB 中的实现类比于 HBase 中 Coprocessor 的 Endpoint 部分, 有点像 mysql 中的存储过程。 简单的说,就是在查询过程中,将部分计算过程下推到各个 Region 上进行。
本文将详细介绍 Coprocessor 在 TiKV 的实现,主要内容包括
- 查询流程
- Table 数据存储格式
- Coprocessor
- 源码简介
查询流程
目前 TiDB 进行的所有查询操作,都会通过 Coprocessor 接口与 TiKV 进行交互。

如图,TiDB 在收到查询请求后,执行过程如下:
- tidb 收到来自客户端的 select 请求。
- tidb 分析该请求,准备执行计划;同时,tidb 向 pd 获取 start_ts。
- tidb 从缓存中获取 information_schema,若没有,从 tikv 获取 information_schema。
- tidb 从 information_schema 中获取到当前用户所操作的 table 的元信息。
- tidb 根据准备好的执行计划,将 tidb 这边的 keyrange 带上 table 的元信息后组织成 tikv 的 keyrange。
- tidb 从缓存或 PD 获取每个 keyrange 所在的 regions 信息。
- tidb 根据 regions 对 keyrange 进行分组。
- tidb 并发向所有 regions 对应的 tikv 分发 select 请求。
- tidb 收到所有结果后,整理数据。
- tidb 执行下一个执行计划 5,或返回客户端数据。
简单的说,就是 TiDB 在收到客户端的查询请求后,切分成一个个以 Range 为单位的子任务, 并行下发到所在的 TIKV 上。
Table 数据存储格式
TiDB 将一个查询操作组织成子任务的形式下发到 TiKV, 以充分利用 TiKV 的计算资源、减少不必要的网络传输。 TiKV 在计算过滤过程中,便涉及到了对数据的存储方式。
对于 TiDB 而言, TiKV 是一个分布式 KV 存储引擎。 TiDB 以行存的方式,将数据转换成 (Key,Value) 存储到 TiKV 上。
目前 table 的数据主要会被组织成两种形式的 (key, value):
- Record Data,
- Index Data
Record Data
Record Data, 即以主键为 Key 的完整行数据。 TiDB 内部会给每一行数据赋予一个连续递增的整数作为其 handle(目前,如果当前表有连续递增的 primary key, 则将其设为 handle)。
其中,Record Data 的编码方式为:
t_${table_id}_r_${handle}=>${v1}${v2}${..}
其中,v1, v2 为对应列的具体数据,目前被组织成 Datum 的数据结构进行统一的编解码。
Index Data
索引数据
以索引为 Key 的指向该行 handle 的数据。
Unique index
唯一索引其 index 值能保证唯一,其编码方式为:
t_${table_id}_i_${index_id}${v1}${v2}=>${handle}
其中, v1,v2 为当前所以的值。
Non-unique index
对于非唯一索引,采用以上方式无法保证不同行的 key 唯一, 所以其 Key 后面加入了 handle:
t_${table_id}_i_${index_id}${v1}${v2}${v...}${handle}=>null
Datum
Datum 是每列具体数据的基本结构,其在 TiKV 中以 enum 的形式实现, 目前支持的基本数据结构如下:
pub enum Datum {
Null,
I64(i64),
U64(u64),
F64(f64),
Dur(Duration),
Bytes(Vec<u8>),
Dec(Decimal),
Time(Time),
Json(Json),
Min,
Max,
}
所以,当 TIDB 收到查询请求时,可以直接通过表的元信息编码出一个 key 的范围,再将请求发到各个涉及region 所在的 TiKV 即可。
以以下查询为例:
select count(*) from t where a+b>5

假设表 t 的数据落在三个 region 上,各个 region 所包含的主键 (handle) 范围如下:
- region1 包含了 t 的 [0,100)
- region2 包含了 t 的 [100,1000)
- region3 包含了 t 的 [1000,+~)
那么我们只需要在各个 region 上分别统计符合条件 a+b>5 的数据,然后在 tidb 再将这三份数据聚合即可。
Coprocessor
Coprocessor 相关接口
目前Coprocessor 支持的接口有以下三种:
- Select 旧的查询下推,目前仅用于 TiSpark, 即将废除。
- DAG 查询下推,新查询下推接口,以应用于 TiDB 中。
- Analyze 统计下推,主要用于统计相关的下推,以协助 join 相关的优化, 以应用于 TiDB。
本文将以 DAG 为重点介绍。
Executor
DAG(Directed Acyclic Graph) 顾名思义,将 SelectRequest 整理成有向无坏图的方式,下发查询请求。

一个 DAG 请求由一系列由 executor 组成的有向无环图组成,executor 又称算子, 所有算子都实现了一个 next 的方法。 每个算子调用前一个算子的 Next 方法作为数据源。
pub trait Executor {
fn next(&mut self) -> Result<Option<Row>>;
}
目前已 TiKV 已支持的 executor 主要由以下几类:
TableScan
对 table 按照主键进行扫描,只会作为 executors 的第一个算子出现。其从底层 kv 系统按主键获取每行数据,并根据需要获取所需列数据。
message TableScan {
optional int64 table_id = 1 [(gogoproto.nullable) = false];
repeated ColumnInfo columns = 2;
optional bool desc = 3 [(gogoproto.nullable) = false];
}
参数说明:
- table_id: 所扫描 table 的编号
- columns: 所关心的列信息
- desc: 是否倒着扫
IndexScan
对 table 的索引进行扫描,只会作为 executors 的第一个算子出现。其从底层 kv 系统按索引获取每行数据,并根据需要获取所需要的索引列(或主键) 数据。
定义如下
message IndexScan {
optional int64 table_id = 1 [(gogoproto.nullable) = false];
optional int64 index_id = 2 [(gogoproto.nullable) = false];
repeated ColumnInfo columns = 3;
optional bool desc = 4 [(gogoproto.nullable) = false];
}
- table_id: 所扫描的 table 编号
- index_id: 所扫描的索引编号
- columns: 所关心的列列表
- desc: 是否倒着扫描
Selection
对上一个算子得到的数据按条件进行过滤。
message Selection {
// Where conditions.
repeated Expr conditions = 1;
}
conditions: 过滤条件列表,每个Expr 为一个条件多叉树, 每个Expr 之前为 AND 连接。 Expr 的定义将在下一章说明
Aggregation
对上一个算子获得的数据进行聚合计算。
message Aggregation {
// Group by clause.
repeated Expr group_by = 1;
// Aggregate functions.
repeated Expr agg_func = 2;
// If it is a stream aggregation.
optional bool streamed = 3 [(gogoproto.nullable) = false];
}
- group_by: 聚合表达式列表
- agg_func: 聚合函数
- stream: 预留字段
TopN
对上一个算子所获取的数据按指定顺序获取 topn
message TopN {
// Order by clause.
repeated ByItem order_by = 1;
optional uint64 limit = 2 [(gogoproto.nullable) = false];
}
- order_by: 排序规则
- limit: 限制个数
Limit
对上一个算子所得到的 limit 条数据进行返回
message Limit {
// Limit the result to be returned.
optional uint64 limit = 1 [(gogoproto.nullable) = false];
}
Expression
在查询过程中,有几种场景需要用到表达式:
- 条件过滤表达式,主要在算子 selection 中用到,对应于带 where 的查询,返回 true/false
- 计算表达式,主要用在算子 selection/groupby/orderby
- 聚合表达式,用于 sum,count,avg, max,min 等聚合计算。
表达式为一个多叉树,在 proto 中的基本结构如下
message Expr {
optional ExprType tp = 1 [(gogoproto.nullable) = false];
optional bytes val = 2;
repeated Expr children = 3;
optional ScalarFuncSig sig = 4;
optional FieldType field_type = 5;
}
目前支持的表达式主要分为以下三种
- Constant
- ColumnRef
- ScalarFunc
常量
只会作为叶子节点出现,其 ExprType 分别对应几类基本数据类型:
- ExprType::Null
- ExprType::Int64, 值以 BigEndian 的形式存在 val 中
- ExprType::Uint64 值以 BigEndian 的形式编码后存在 val 中
- ExprType::String 值转成 byte 存在 val 中
- ExprType::Bytes 值存在 val 中
- ExprType::Float32 值以 BigEndian 的形式编码后存在 val 中
- ExprType::Float64 值以 BigEndian 的形式编码后存在 val 中
- ExprType::MysqlTime 值转成 i64 后 BigEndian 编码存在 val 中,具体参考 tidb 的实现。
- ExprType::MysqlDuration 值以 tidb 定义的 Decimal 形式存在 val 中,具体参考 tidb 的实现
- ExprType::MysqlDecimal 值编解码参考 tidb
- ExprType::MysqlJson 值编解码参考 tidb
函数签名
对应 type 为 ExprType::ScalarFunc,具体函数名称定义在 ScalarFuncSig 中, 函数参数列表存于 children 中
列的引用
对应 type 为 ExprType::ColumnRef, 只会作为叶子节点出现,某列的指针,其在 tablescan/indexscan 中涉及 columns 的下标 offset 存于val 中
示例:
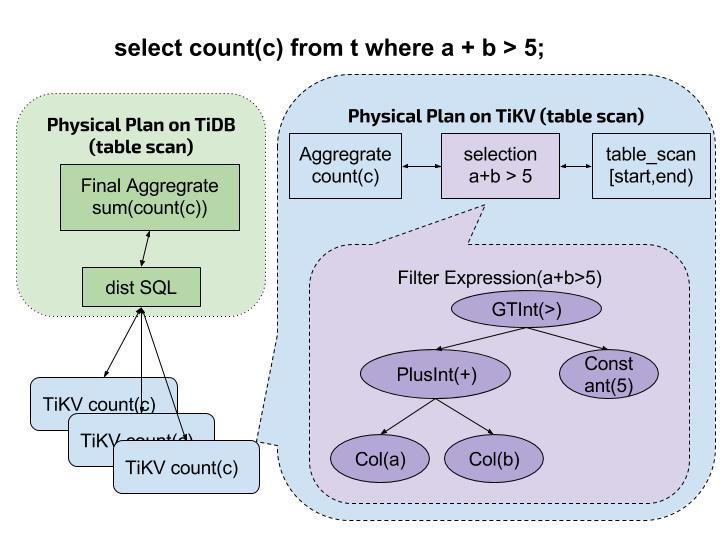
如图,当 TiDB 收到来自客户端的查询请求
Select count(*) from t where a + b > 5
时,执行顺序如下:
- TiDB 对 SQL 进行解析,组织成对应的表达式,下推给 TiKV
- TiKV 收到请求后,循环步骤 3-5
- 获取下一行完整数据,并按列解析。 若下一行数据不存在,则进行步骤 6
- 使用参数中的 where 表达式对数据进行过滤。
- 若上一条件符合, 放入聚合计算。继续步骤 3.
- TiKV 向 TiDB 返回聚合计算结果。
- TiDB 对所有涉及的结果进行二次聚合,返回给客户端。
源码简介
TiKV 的 Coprocessor 源码阅读入口为 https://github.com/pingcap/tikv/blob/master/src/server/service/kv.rs#L744 中的
fn coprocessor(&self, ctx: RpcContext, req: Request, sink: UnarySink<Response>) {
其会向 src/coprocessor 目录下的 endpoint.rs 发起任务。 以下主要对 coprocessor 目录进行简介。
源码根目录 Coprocessor
tree src/coprocessor -L 1
src/coprocessor
├── codec
├── dag
├── endpoint.rs
├── metrics.rs
├── mod.rs
├── select
└── statistics
- codec: 主要为编解码相关源码
- dag: 主要为 DAG 接口的实现相关代码
- endpoint.rs: coprocessor 处理入口
- metrics.rs: 监控指标相关
- select: 旧的 Select 接口相关代码, 待废除。
- statistics: 统计相关接口代码,主要用于 客户端对 join 算法的优化。
源码目录 dag
src/coprocessor/dag
├── dag.rs
├── executor
├── expr
└── mod.rs
- dag.rs: dag 接口处理入口
- executor: 各个 executor 源码,包括 tablescan, indexscan, selection, etc
- expr: 表达式实现入口
源码目录 dag/executor
src/coprocessor/dag/executor
├── aggregation.rs
├── index_scan.rs
├── limit.rs
├── mod.rs
├── scanner.rs
├── selection.rs
├── table_scan.rs
└── topn.rs
- aggregation.rs: 算子 aggregation
- index_scan.rs: 算子 index_scan
- limit.rs: 算子 limit 的实现
- selection.rs: 算子 selection 的实现
- table_scan.rs: 算子 table_scan 的实现
- topn.rs: 算子 topn 的实现
- scanner.rs: 从存储中获取 kv 接口实现
源码目录 dag/expr
src/coprocessor/dag/expr
├── arithmetic.rs
├── builtin_cast.rs
├── builtin_control.rs
├── builtin_op.rs
├── column.rs
├── compare.rs
├── constant.rs
├── fncall.rs
├── json.rs
├── math.rs
└── mod.rs
- column.rs 列引用表达式相关实现, ColumnRef
- constant.rs 常量表达式相关实现
- fncall.rs 函数签名类型表达式处理入口
其中函数签名表达式所涉及的函数实现源码如下:
- arithmetic.rs 算术运算相关的函数签名实现,加减乘除
- builtin_cast.rs cast 相关的函数签名实现
- builtin_control.rs control 相关函数签名实现,如 if/if_null/case_when
- builtin_op.rs 位运算相关函数签名实现,如 and/or/xor/is_true/is_false..
- compare.rs: 比较相关函数签名实现
- json.rs: json 相关函数签名实现
- math.rs: 数学方法相关函数签名实现, 如 abs/ceil
