Google Percolator 的事务模型
Percolator 简介
Percolator是由Google公司开发的、为大数据集群进行增量处理更新的系统,主要用于google网页搜索索引服务。使用基于Percolator的增量处理系统代替原有的批处理索引系统后,Google在处理同样数据量的文档时,将文档的平均搜索延时降低了50%。
Percolator的特点如下
- 为增量处理定制
- 处理结果强一致
- 针对大数据量(小数据量用传统的数据库即可)
Percolator为可扩展的增量处理提供了两个主要抽象:
- 基于随机存取库的ACID事务
- 观察者(observers)–一种用于处理增量计算的方式
事务
Percolator 提供了跨行、跨表的、基于快照隔离的ACID事务。
Snapshop isolation
Percolator 使用Bigtable的时间戳记维度实现了数据的多版本化。多版本化保证了快照隔离snapshot isolation级别,优点如下:
- 对读操作:使得每个读操作都能够从一个带时间戳的稳定快照获取。
- 对写操作,能很好的应对写写冲突:若事务A和B并发去写一个同一个元素,最多只有一个会提交成功。
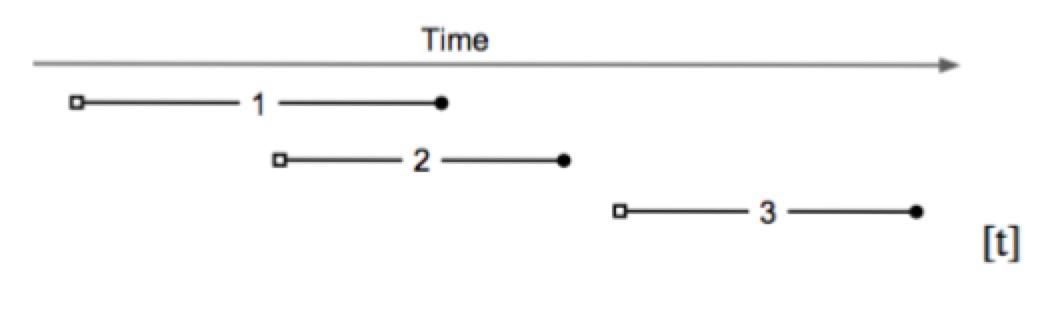
如图,基于快照隔离的事务,开始于一个开始时间戳a start timestamp(图内为小空格),结束于一个提交时间戳a commit timestamp(图内为小黑球)。本例包含以下信息:
- 由于
Transaction 2的开始时间戳start timestamp小于Transaction 1的提交时间戳commit timestamp,所以Transaction 2不能看到Transaction 1的提交信息。 Transaction 3可以看到Transaction 2和Transaction 1的提交信息。Transaction 1和Transaction 2并发执行:如果它们对同一项进行写入,至少有一个会失败。
Lock
Percolator 的请求会直接反映到对Bigtable的修改上,由于Bigtable没有提供便捷的冲突解决和锁管理,所以Percolator需要独立实现一套锁管理机制。锁的管理必须满足以下条件:
- 能直面机器故障:若一个锁在两阶段提交时消失,系统可能将两个有冲突的事务都提交。
- 高吞吐量:上千台机器会同时请求获取锁。
- 低延时:每个
Get()操作都需要读取一次锁
故其锁服务在实现时,需要做到:
- 多副本 ==> 应对故障
- distributed&balance ==> handle load
- 写入持久化存储系统
BigTable能够满足以上所有要求。所以Percolator在实现时,将实际的数据存于Bigtable中。
Columns in Bigtable
Percolator在BigTable上抽象了五个Columns,其中三个跟事务相关,其定义如下
Lock
事务产生的锁,未提交的事务会写本项,会包含primary lock的位置。其映射关系为
${key,start_ts}=>${primary_key,lock_type,..etc}
- ${key} 数据的key
- ${start_ts} 事务开始时间
- ${primary} 该事务的
primary的引用.primary是在事务执行时,从待修改的keys中选择一个作为primary,其余的则作为secondary.
Write
已提交的数据信息,存储数据所对应的时间戳。其映射关系为
${key,commit_ts}=>${start_ts}
- ${key} 数据的key
- ${commit_ts} 事务的提交时间
- ${start_ts} 该事务的开始时间,指向该数据在
data中的实际存储位置。
Data
具体存储数据集,映射关系为
${key,start_ts} => ${value}
- ${key} 真实的key
- ${start_ts} 对应事务的开始时间
- ${value} 真实的数据值
案例
银行转账,Bob 向 Joe 转账7元。该事务于start timestamp =7 开始,commit timestamp=8 结束。具体过程如下:
- 初始状态下,Bob 的帐户下有10(首先查询
column write获取最新时间戳数据,获取到data@5,然后从column data里面获取时间戳为5的数据,即$10),Joe 的帐户下有2。
- 转账开始,使用
stat timestamp=7作为当前事务的开始时间戳,将Bob选为本事务的primary,通过写入Column Lock锁定Bob的帐户,同时将数据7:$3写入到Column,data列。
- 同样的,使用
stat timestamp=7,锁定Joe的帐户,并将Joe改变后的余额写入到Column,data,当前锁作为secondary并存储一个指向primary的引用(当失败时,能够快速定位到primary锁,并根据其状态异步清理)
- 事务带着当前时间戳
commit timestamp=8进入commit阶段:删除primary所在的lock,并在write列中写入从提交时间戳指向数据存储的一个指针commit_ts=>data @7。至此,读请求过来时将看到Bob的余额为3。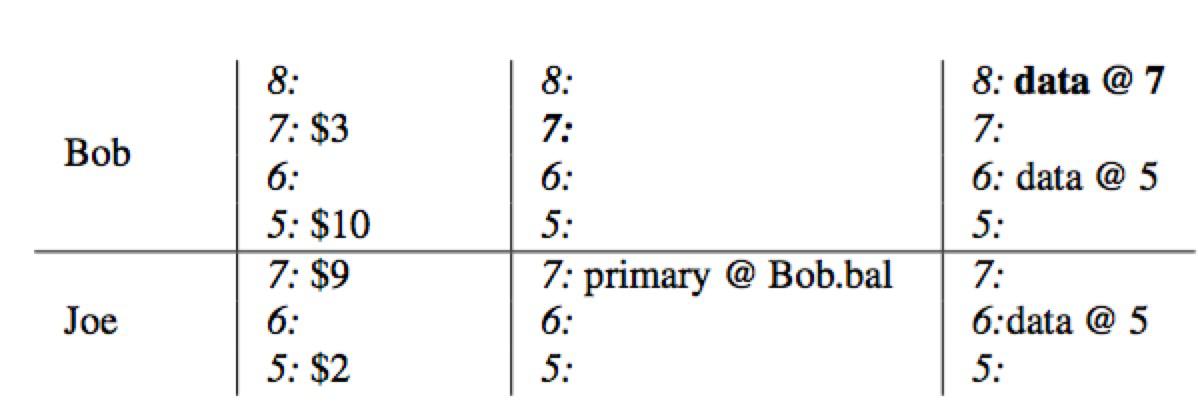
- 依次在
secondary项中写入wirte并清理锁,整个事务提交结束。在本例中,只有一个secondary:Joe.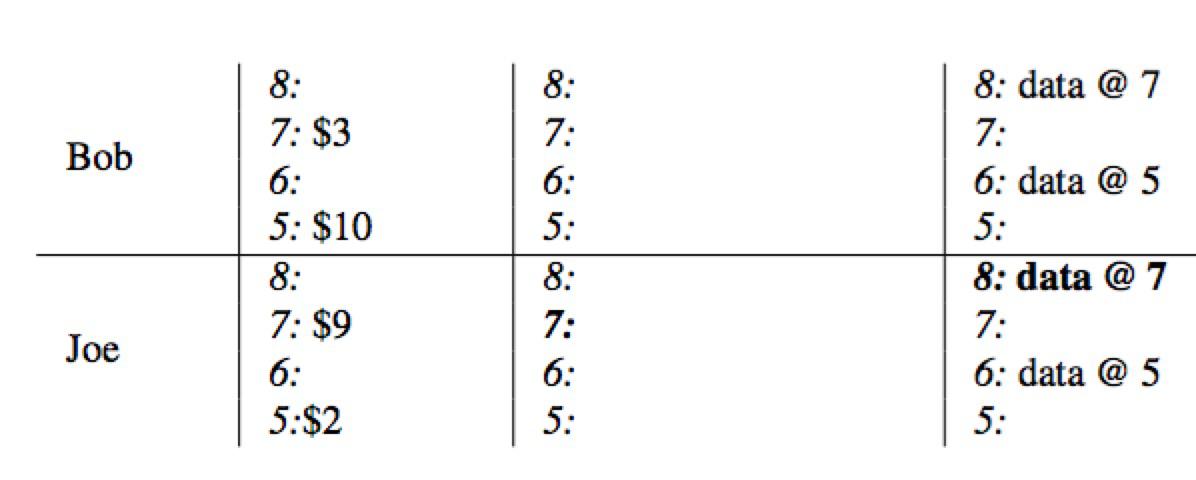
事务处理流程
Prewrite
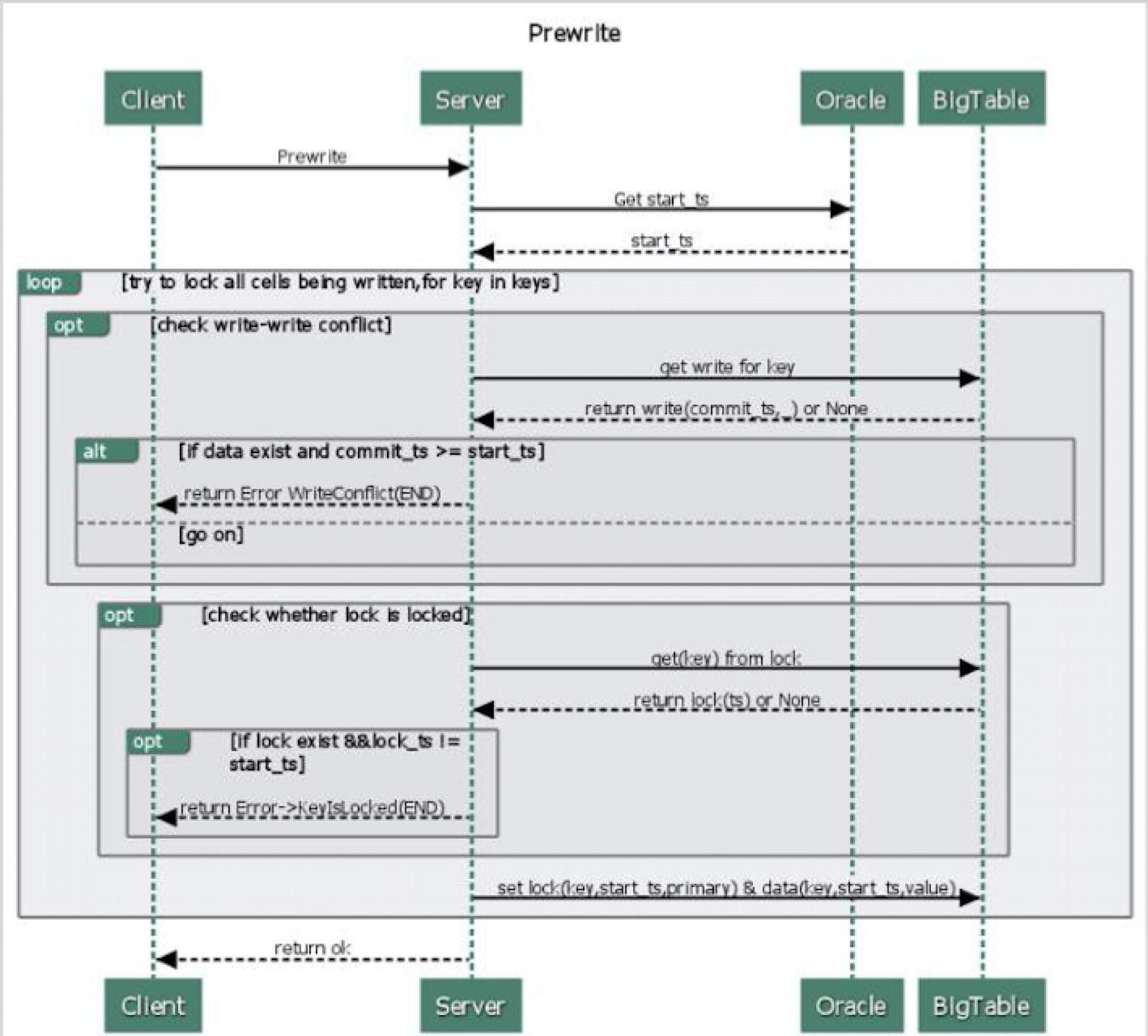
Prewrite是事务两阶段提交的第一步,其从Oracle获取代表当前物理时间的全局唯一时间戳作为当前事务的start_ts,尝试对所有被写的元素加锁(为应对客户端故障,pecolactor为所有需要写的key选出一个作为primary,其余的作为secondary.),将实际数据存入Bigtable。其中每个key的处理过程如下,中间出现失败,则整个prewrite失败:
- 检查
write-write冲突:从BigTable的write列中获取当前key的最新数据,若其commit_ts大于等于start_ts,说明存在更新版本的已提交事务,返回WriteConflict错误,结束。 - 检查
key是否已被锁上,如果key的锁已存在,返回KeyIsLock的错误,结束 - 往BigTable的
lock列写入lock(start_ts,key,primary)为当前key加锁,若当前key被选为primary,则标记为primary,若为secondary,则标明指向primary的信息 - 往BigTable的
data列写入的数据data(key,start_ts,value)。
Commit
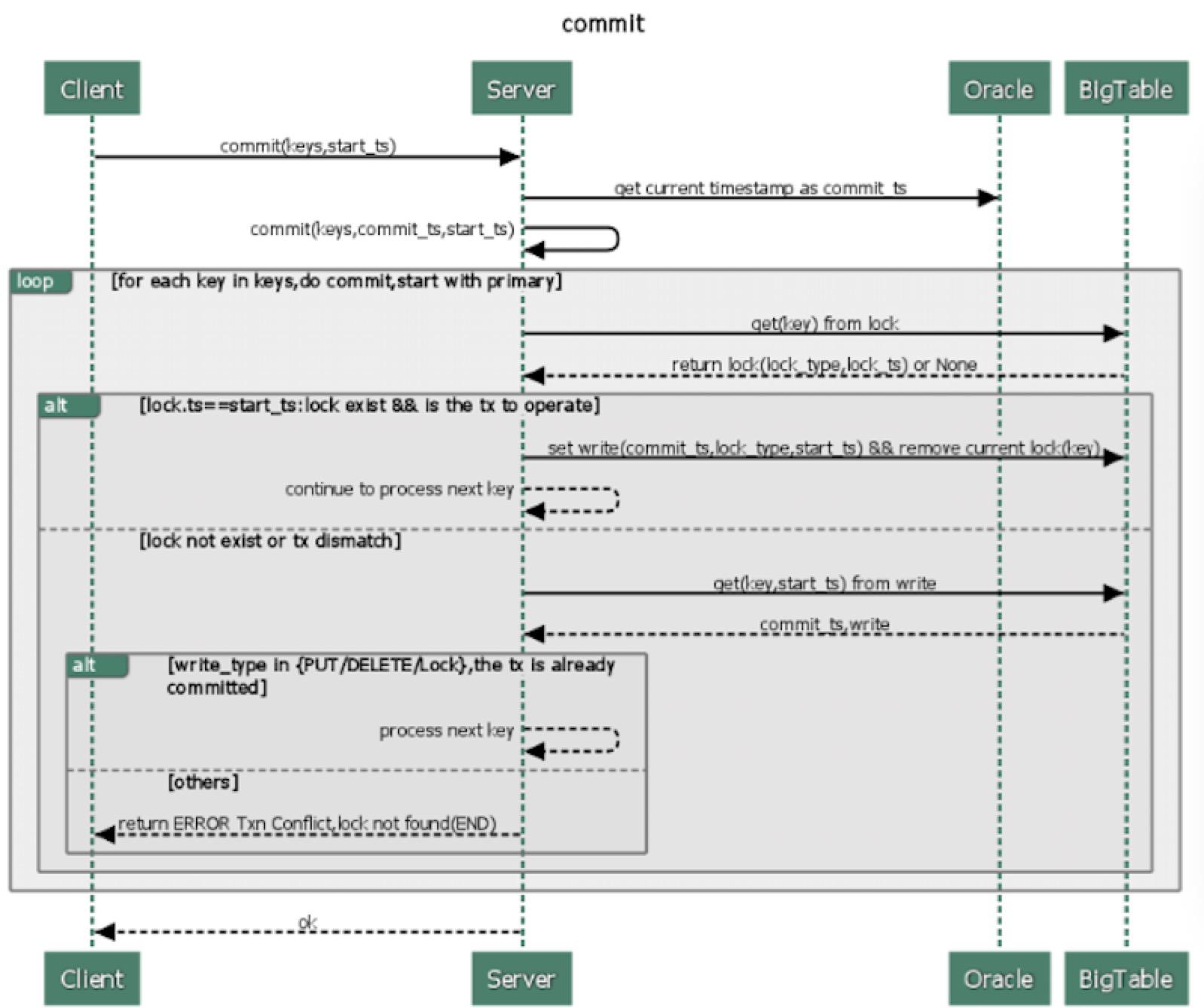
Prewrite成功后,该事务可能会被提交从而进入第二阶段--Commit
同样的,在事务提交的开始阶段,将从Oracle获取时间戳作为commit_ts代表事务的真正提交时间。然后,将依次对各个key进行提交(第一个为parimary),释放锁,打上提交标识。每个key的提交过程具体如下:
- 从Bigtable获取key的lock,检查其合法性,若非法,则返回失败
- 将
commit_ts,当前数据在data列中的位置,等其它相关信息写入write列。 - 将当前key所在的
lock从 Bigtable的lock列删除,至此,该key的锁被释放。
write 记录着key的提交记录,当客户端读取一个key时,会从write表中读取key所对应数据在data列中的存储位置,然后从data列中读取真正的数据。同时,一旦primary 被提交成功后,整个事务对外就算提交成功了。
Get
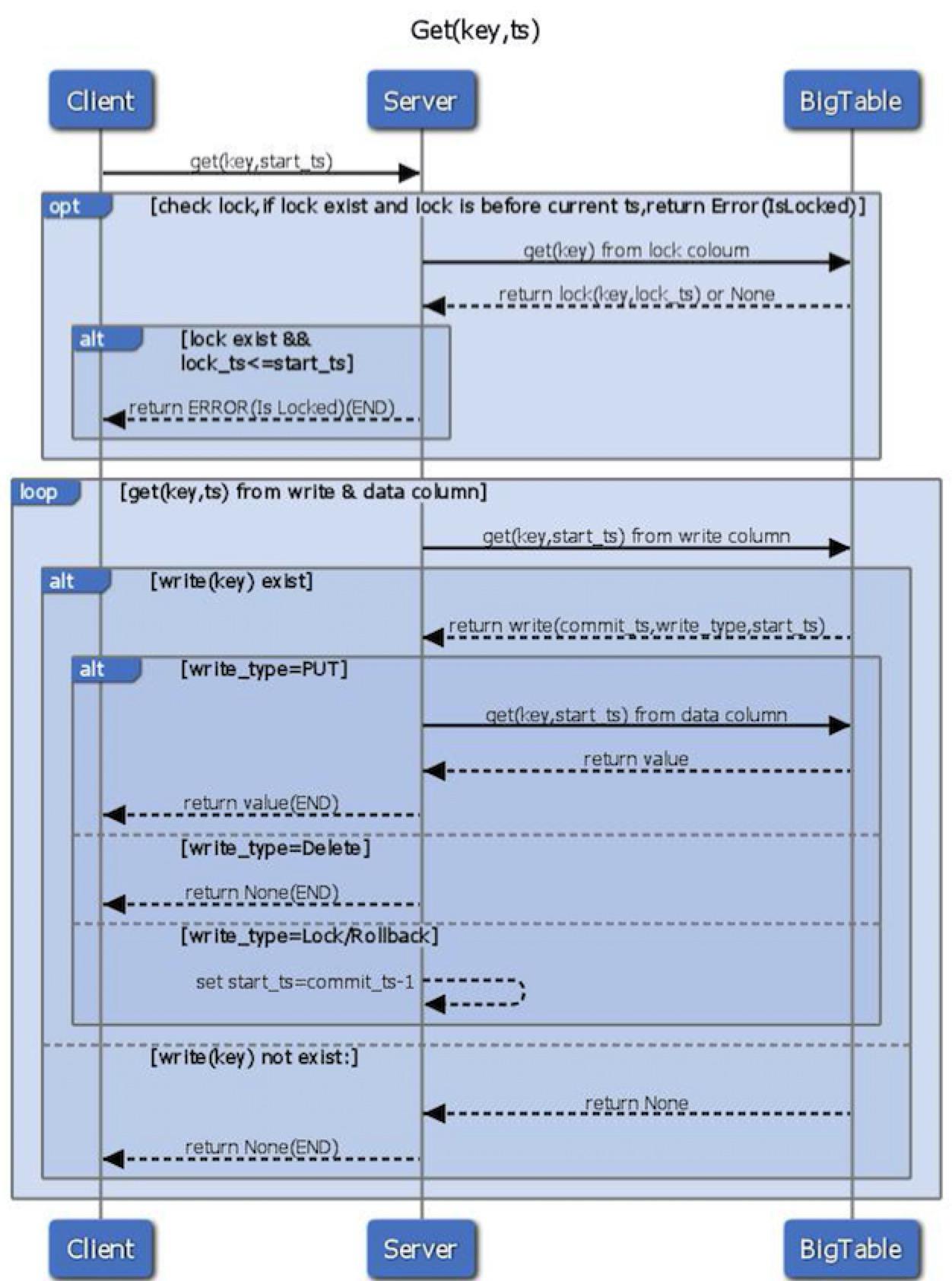
Get操作首先检查[0,start_ts]时间区间内Lock是否存在,若存在,则返回错误- 如果不存在有冲突的
Lock,则获取在write中合法的最新提交记录指向的在data中的位置 - 根据步骤2获取的内容,从
data中获取到相应的数据并返回。
异常处理(异步清理锁)
若客户端在Commit一个事务时,出现了异常,Prepare 时产生的锁会被留下。为避免将新事务hang住,Percolator必须清理这些锁。
Percolator用lazy方式处理这些锁:当事务A在执行时,发现事务B造成的锁冲突,事务A将决定事务B是否失败,以及清理事务B的那些锁。
对事务A而言,能准确地判断事务B是否成功是关键。Percolator为每个事务设计了一个元素cell作为事务是否成功的同步标准,该元素产生的lock即为primary lock。A和B事务都能确定事务B的primary lock(因为这个priarmy lock被写入了B事务其它所有涉及元素的lock里面)。执行一个清理clean up或者提交commit操作需要修改该primary lock,由于这些修改是基于Bigtable去做,所以只有一个清理或提交会成功。注意:
- 在B提交
commit之前,它会先确保其primary lock被write record所替代(即往primary的write写提交数据,并删除对应的lock)。 - 在A清理B的锁之前,A必须检查B的
primary以确保B未被提交,如果B的primary存在,则B的锁可以被安全的清理掉。
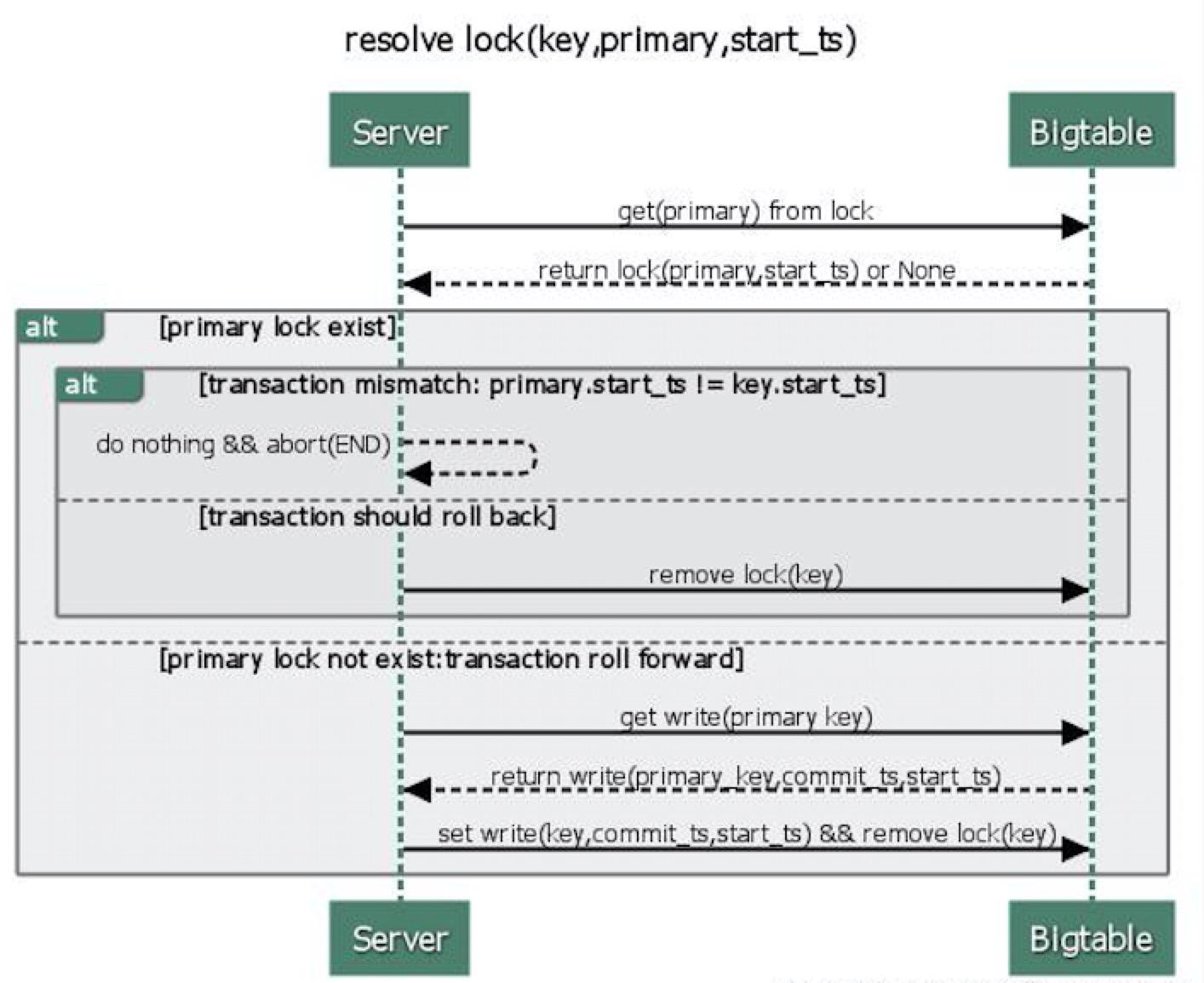
当客户端在执行两阶段提交的commit阶段失败时,事务依旧会留下一个提交点commit point(至少一条记录会被写入write中),但可能会留下一些lock未被处理掉。一个事务能够从其primary lock中获取到执行情况:
- 如果
priarmy lock已被write所替代,也就是说该事务已被提交,事务需要roll forword,也就是对所有涉及到的、未完成提交的数据,用write记录替代标准的锁standed lock。 - 如果
primary lock存在,事务被roll back(因为我们总是最先提交primary,所以primary未被提交时,可以安全地执行回滚)
